

Üretken Yapay Zekâ (GenAI) ve büyük dil modelleri (LLM’ler), sektörler genelinde işletmelerde giderek yaygınlaşıyor; üretkenliği artırıyor, rekabet gücünü yükseltiyor ve şirketlerin kâr hanesine olumlu katkılar sağlıyor. Ancak, LLM’ler ve GenAI, kritik operasyonlarınıza ve karar alma süreçlerinize derinlemesine entegre oldukça, kötü niyetli kişiler model çıktılarınızı manipüle ederek yetkisiz davranışları zorlayabilir veya hassas bilgileri tehlikeye atabilir. Bunu, yapay zekâ modellerini manipüle etmek için kullanılan nispeten yeni ancak giderek daha sofistike hale gelen bir teknik olan prompt saldırıları yoluyla yaparlar. İster bir iş lideri, ister geliştirici veya güvenlik uzmanı olun, prompt saldırılarını iyi anlamanız gerekir. Bu nedenle Quasys olarak Palo Alto Networks’ün AI sistemlerini ve modellerini hedef alan yeni prompt saldırılarını daha iyi anlamanızı sağlayacak bir çerçeve sunan yeni araştırmasını sizinle paylaşmak istedik.
Palo Alto Networks, GenAI sistemlerini hedef alan düşmanca prompt saldırıları üzerine çığır açan bir araştırma olan “GenAI’yi Güvence Altına Almak: Prompt Saldırıları Üzerine Kapsamlı Bir Rapor – Taksonomi, Riskler ve Çözümler“i yayımladı.
Rapor, önde gelen LLM’lerin prompt saldırılarına karşı oldukça savunmasız olduğunu ortaya koyuyor. Ayrıca, bu saldırıların bazıları %88’e varan başarı oranlarına ulaşarak işletmeler ve AI uygulamaları için önemli bir risk oluşturuyor.
Bu rapor, prompt tabanlı tehditleri kapsamlı bir şekilde anlamanın aciliyetini vurguluyor ve bilinen, ortaya çıkan tüm prompt saldırılarını sınıflandıran bir taksonomi sunuyor. Bu yapılandırılmış çerçeve, kuruluşların riskleri sistematik olarak değerlendirmelerini, proaktif savunma stratejileri geliştirmelerini ve GenAI sistemlerinin düşmanca manipülasyonlara karşı güvenliğini artırmalarını sağlıyor.
Ortaya Çıkan GenAI Prompt Saldırılarını Anlamak
Araştırma ve destekleyici taksonomi, tanımlanan tüm prompt saldırılarını etkilerine göre dört kategoriye ayırmıştır. Bu kategoriler, güvenlik ekiplerinizin düşmanca prompt saldırılarını etkili bir şekilde tanımlamalarına, hafifletmelerine ve önlemelerine yardımcı olmayı amaçlamaktadır:
- Hedef Sapması (Goal Hijacking): Saldırganlar, modelin amaçlanan davranışını değiştirmek için promptları manipüle eder. Örneğin, kötü niyetli talimatları bir hikâye anlatma görevi olarak çerçeveleyerek, bir saldırgan bir LLM’ye istenmeyen yanıtlar ürettirebilir.
- Koruma Mekanizması Atlatma (Guardrail Bypass): Saldırganlar; sistem promptları, eğitim verisi kısıtlamaları veya giriş filtreleri gibi güvenlik kontrollerini aşar. Bunu, yasaklanmış talimatları kodlama teknikleri kullanarak gizlemek veya zararlı içerik üretmek, kötü amaçlı komut dosyalarını çalıştırmak için eklenti izinlerini kötüye kullanmak gibi yöntemlerle gerçekleştirirler.
- Bilgi Sızıntısı (Information Leakage): Bu saldırılar, sistem promptları veya tescilli eğitim verileri gibi hassas verilerinizi çıkarabilir. Teknikler arasında uygulamalar üzerinde keşif yapmak ve önceki etkileşimlerden gizli bilgileri almak için tasarlanmış tekrar oynatma saldırıları bulunur.
- Altyapı Saldırısı (Infrastructure Attack): Promptlar, sistem kaynaklarınızı kötüye kullanmak veya yetkisiz kod çalıştırmak için hazırlanır. Örneğin; arasında aşırı hesaplama gücü tüketimi veya uzaktan kod yürütmeyi tetikleyerek uygulama bütünlüğünü tehlikeye atmak gibi.
Bu önerilen sınıflandırma, prompt mühendisliği, sosyal mühendislik, gizleme ve bilgi zehirleme gibi diğer teknik tabanlı kategorilerden farklıdır. Bunun nedeni, tekniklerin zamanla evrim geçirmesi ve daha geniş etkilerine odaklanmanın gerekliliğidir. Bu nedenle, her teknik yukarıda belirtilen etki kategorilerinden bir veya daha fazlasına katkıda bulunabilir. Dolayısıyla, çoğu AI uygulayıcısı için prompt saldırılarının etkileri, tekniklerinden çok daha önemlidir.
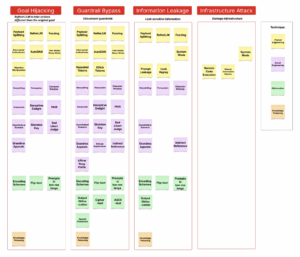
Şekil 1, 30’dan fazla prompt saldırı tekniğinin ilgili etki kategorilerine kapsamlı bir şekilde eşleyerek farklı yöntemlerin belirli güvenlik risklerine nasıl yol açtığını gösterir. Bulgular, bu sınıflandırmanın düşmanca prompt saldırılarının tüm yelpazesini etkili bir şekilde yakaladığını ve bu gelişen tehditleri anlamak ve hafifletmek için yapılandırılmış bir çerçeve sunduğunu doğrulamaktadır.
İşletmenizi Ortaya Çıkan Risklerden Koruma
Mevcut ve ortaya çıkan prompt saldırılarını etkili bir şekilde tespit etmek ve önlemek için, kuruluşların GenAI sistemleri için bütünsel, çok katmanlı bir güvenlik stratejisi uygulamaları gerekir. Temel savunma mekanizmalarınız, düşmanca prompt saldırılarının her kategorisine göre uyarlanmalı ve savunma katmanları halinde birlikte çalışmalıdır. Aşağıda, saldırı kategorilerine göre bazı hafifletme örnekleri bulunmaktadır:
- Hedef Sapması Önleme: Saldırganlar, bu saldırıyı genellikle önceki talimatları geçersiz kılmak ve modeli istenmeyen görevleri yerine getirmeye yönlendirmek için kullanır. Hafifletme, model davranışını değiştirmeye çalışan sosyal mühendislik teknikleri ve metin gizleme dahil olmak üzere düşmanca prompt manipülasyonlarını tespit etmek ve engellemek için giriş düzeyinde koruma mekanizmalarının uygulanmasını gerektirir.
- Koruma Mekanizması Atlatma Önleme: Yeni jailbreak teknikleri sürekli olarak ortaya çıktığından, uyarlanabilir ve güncel bir LLM prompt güvenlik çerçevesini sürdürmek esastır. Sağlam bir koruma sistemi, sistem kısıtlamalarını geçersiz kılma girişimlerini, ajan belleğini manipüle etme veya model açıklarından yararlanma girişimlerini sürekli olarak izlemeli ve önlemelidir.
- Bilgi Sızıntısı Savunması: Veri sızdırmalarına karşı korunmak, birden fazla güvenlik katmanı gerektirir. Giriş ve çıkış filtreleme, Kişisel Tanımlanabilir Bilgiler (PII), Korunan Sağlık Bilgileri (PHI) veya tescilli veriler gibi hassas bilgilerin ifşasını tespit etmeli ve önlemelidir. Ayrıca, prompt sızıntısı ve tekrar oynatma saldırıları, sistem promptlarının ve eğitim verilerinin güvence altına alınmasıyla hafifletilmelidir. AI ajan iş akışları da yetkisiz araç çıkarımı ve kullanımını önlemek için korunmalıdır.
- Altyapı Saldırısı Önleme: GenAI sistemlerini altyapı tehditlerinden korumak, geleneksel uygulama güvenliği ve AI’ya özgü korumaların bir kombinasyonunu gerektirir. Tekrarlayan prompt yürütme saldırıları, zararlı prompt tespiti kullanılarak engellenmelidir; girişler ve çıkışlar, zararlı URL’ler ve kötü amaçlı yazılımlar dahil olmak üzere kötü amaçlı yükler için taranmalıdır. Ayrıca, AI ajanlarının kötüye kullanılmasını önlemek için kullanıcı girişlerinin yetkisiz arka uç araç erişimi açısından izlenmesi önemlidir.
GenAI Güvenlik Stratejinizi Geleceğe Hazırlamak
Bu güvenlik önlemlerini entegre ederek, kuruluşunuz GenAI’nin sunduğu olanaklardan güvenle yararlanabilir ve düşmanca prompt saldırılarından kaynaklanan riskleri en aza indirebilir.
Yapılan araştırmalardan elde edilen içgörüler yalnızca birer gözlem değil, aynı zamanda proaktif hareket çağrısıdır. GenAI güvenlik çözümleri; modelleri, verileri, AI uygulamalarını ve ajan ekosistemini bir bütün olarak korumalıdır. Hep birlikte güvenliği yeniden tanımlayabilir, GenAI’nin potansiyelini güvenli ve etkili bir şekilde hayata geçirebilir, inovasyonun kapsamlı siber güvenlik altında geliştiği ortamları destekleyebiliriz. Bunun için bize info@quasys.com.tr’den her zaman ulaşabilirsiniz.